


Complexité
La complexité est un facteur impliqué dans un processus complexe. En ce qui concerne les algorithmes et les structures de données, il peut s’agir du tempsou de l’ espace (c’est-à-dire de la mémoire informatique) nécessaire pour effectuer une tâche spécifique (recherche, tri ou accès aux données) sur une structure de données donnée. L'efficacité de l'exécution d'une tâche dépend du nombre d'opérations requises pour terminer une tâche.
Sortir les ordures peut nécessiter 3 étapes (attacher un sac à ordures, le sortir et le déposer dans une benne à ordures). Sortir les ordures peut sembler simple, mais si vous les sortez après une longue semaine de travaux, vous risquez de ne pas pouvoir mener à bien cette tâche en raison d'un manque d'espace dans la benne à ordures.
Passer l'aspirateur dans une pièce peut nécessiter de nombreuses étapes répétitives (l'allumer, balayer la tête d'aspirateur de manière répétée sur un sol et l'éteindre). Plus une pièce est grande, plus vous devrez passer une tête d'aspirateur sur son sol. Ainsi, plus il faudra de temps pour aspirer la pièce.
Il existe donc une relation de cause à effet directe entre le nombre d'opérations effectuées et le nombre d'éléments exécutés. Avoir beaucoup de détritus (éléments) nécessite de les enlever plusieurs fois. Cela peut conduire à un problème de complexité de l' espace . Avoir beaucoup de pieds carrés (éléments) nécessite de passer plusieurs fois une tête d'aspirateur sur un sol. Cela peut entraîner un problème de complexité temporelle .
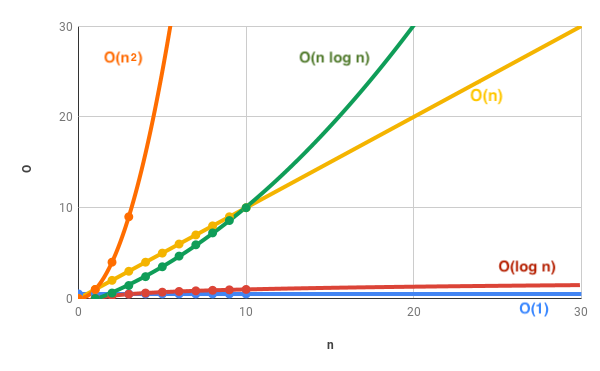
Que vous retiriez les ordures ou aspiriez une pièce , vous pourriez dire que le nombre d'opérations ( O ) augmente exactement avec le nombre d'éléments ( n ) . Si j'ai 1 sac poubelle, je dois sortir la poubelle une fois. Si j'ai 2 sacs poubelle, je dois effectuer la même tâche deux fois, en supposant que vous ne pouvez pas physiquement soulever plus d'un sac à la fois. Ainsi, le Big-O de ces tâches est O = n ou O = fonction (n) ou O (n) . Il s’agit d’une complexité linéaire (une ligne droite avec une correspondance 1 opération: 1 correspondance). Ainsi, 30 opérations sont effectuées sur 30 éléments (ligne jaune sur le graphique).
Ceci est similaire à ce qui se passe lorsque l'on considère les algorithmes et les structures de données.
Recherches
Recherche linéaire
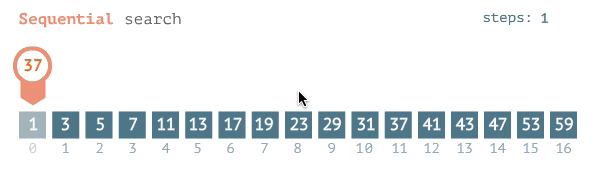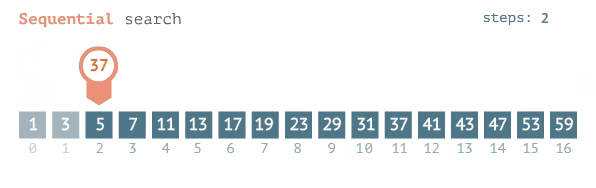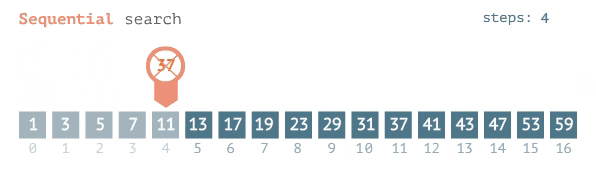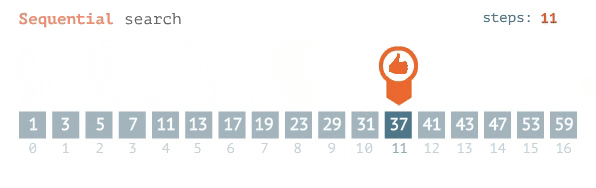
Le meilleur des cas pour rechercher un élément dans une liste ordonnée, les uns après les autres, est une constante O (1) , en supposant qu'il s'agisse du premier élément de votre liste. Ainsi, si l'élément que vous recherchez est toujours répertorié en premier, quelle que soit la taille de votre liste, vous le trouverez en un instant. La complexité de votre recherche est constante avec la taille de la liste. La moyenne au pire des cas de ce type de recherche est une complexité linéaire ou O (n). En d'autres termes, pour n éléments, je dois chercher n fois avant de trouver mon élément, d'où une recherche linéaire.
Recherche binaire
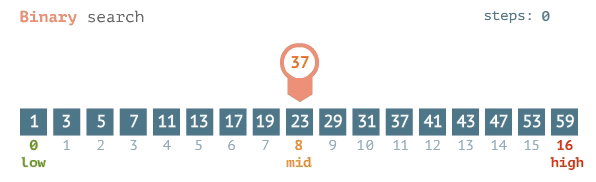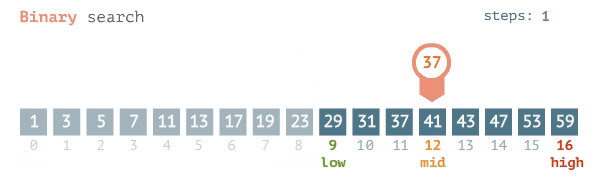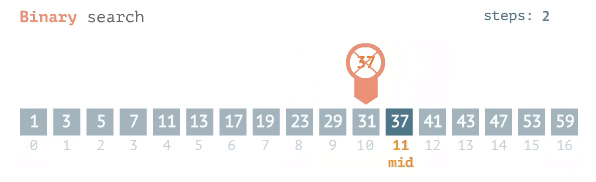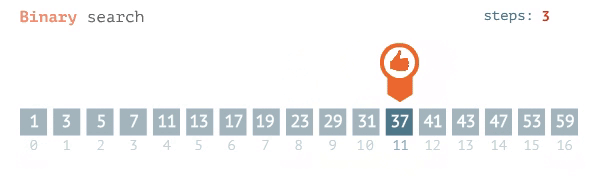
Pour une recherche binaire, le meilleur des cas est O (1), ce qui signifie que l'élément de votre recherche est situé au centre. Le cas le plus défavorable est la base de journal 2 sur n ou:

Le logarithme ou log est un moyen d’exprimer un exposant pour une base donnée. Donc, s’il y avait 16 éléments (n = 16), il faudrait au pire 4 étapes pour trouver le nombre 15 (exposant = 4).
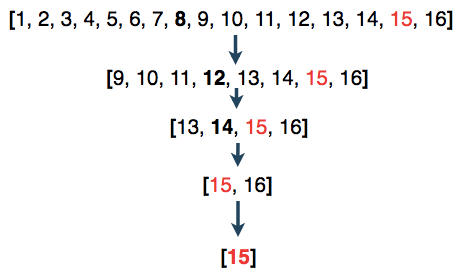
Ou simplement: O (log n)

Trie
Bulle
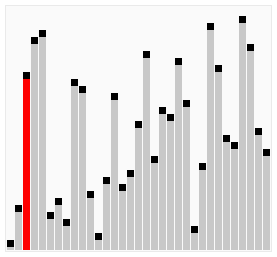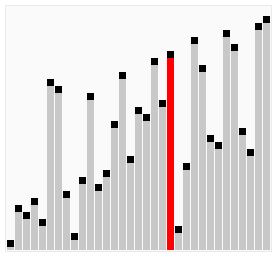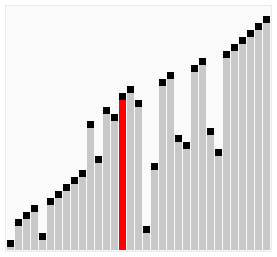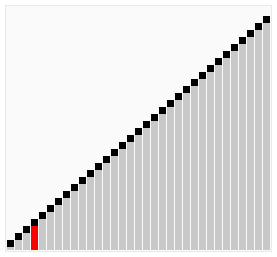
Dans le tri à bulles, chaque élément est comparé au reste de la collection pour déterminer la valeur la plus élevée à bouillonner. Pour cette raison, en moyenne au pire des cas , sa complexité est O (n²) . Pensez à une boucle imbriquée dans une autre boucle.

Donc, pour chaque article, vous le comparez au reste de votre collection. Cela revient à 16 comparaisons (ou opérations) pour 4 éléments (4² = 16). Le meilleur des cas est si votre collection est presque triée, sauf pour un seul élément. Cela équivaudrait à une seule série de comparaisons. C'est-à-dire qu'il faut quatre comparaisons pour faire apparaître un membre d'une collection de quatre éléments, ce qui représente une complexité de O (n) .
Sélection

Contrairement au tri à bulle , au lieu de faire remonter la valeur la plus élevée, le tri par sélection sélectionne la valeur la plus basse pour la permuter aux positions les plus anciennes. Mais, comme il est nécessaire de comparer chaque élément au reste de la collection, il présente également une complexité de O (n²) .
Insertion
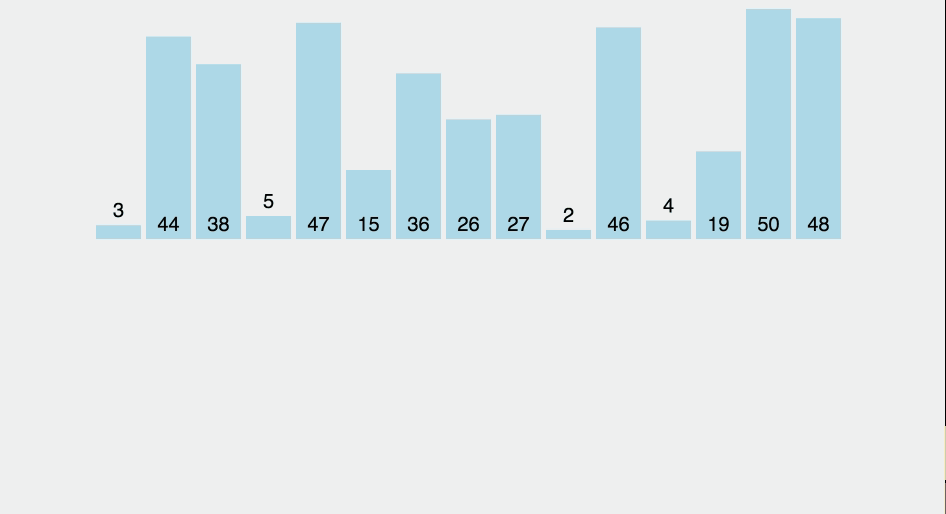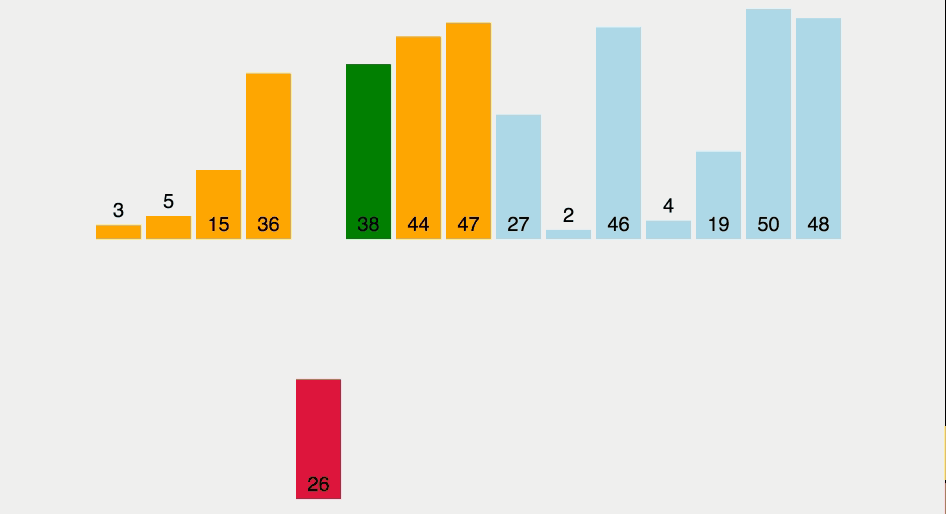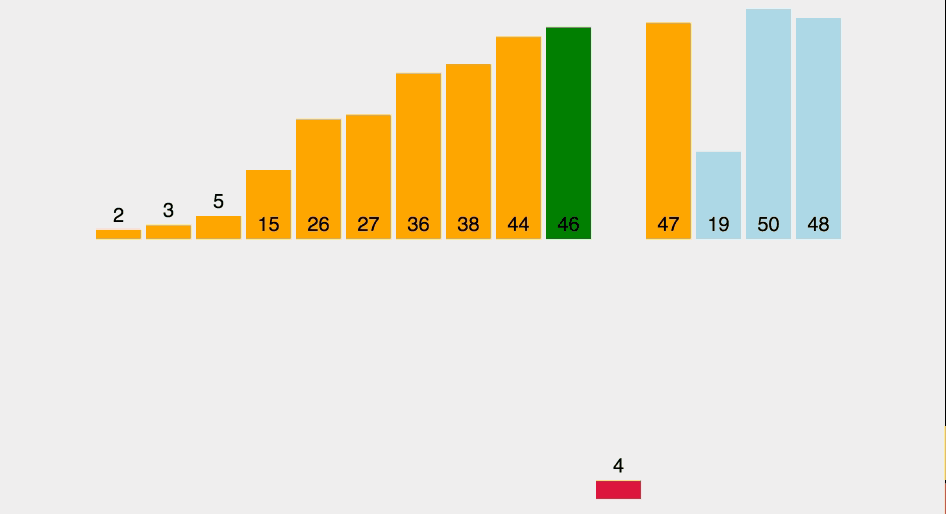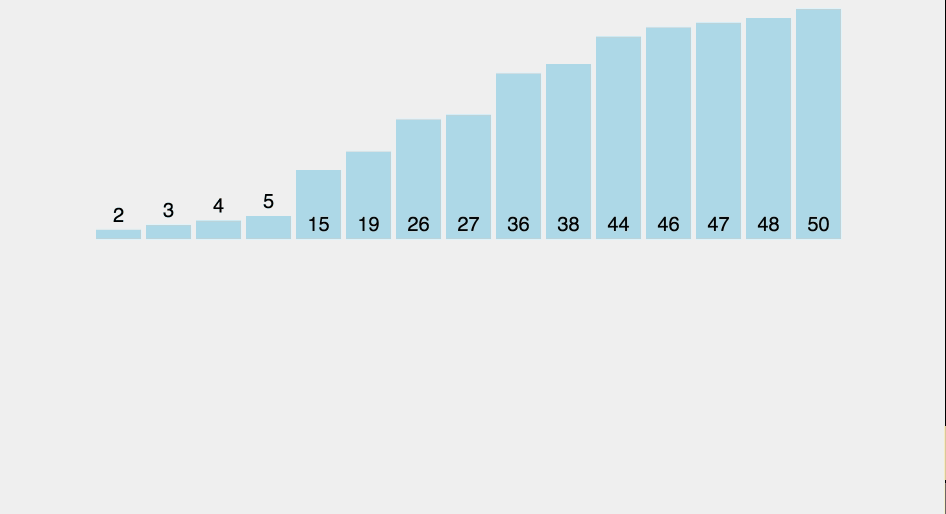
Contrairement aux tris à bulles et à la sélection , le tri par insertion insère l'élément dans sa position correcte. Mais, comme les types précédents, cela nécessite également de comparer chaque élément au reste de la collection. Par conséquent, il présente une complexité moyenne à extrême dans le pire des cas de O (n²) . Comme pour le tri à bulle , s'il ne reste qu'un élément à trier, il suffit d'un seul tour de comparaisons pour l'insérer à la bonne position. C’est-à-dire qu’il présente la meilleure complexité de cas O (n) .
Structures de données
Tableaux
Puisqu'il faut une seule étape pour accéder à un élément d'un tableau via son index ou pour ajouter / supprimer un élément à la fin d'un tableau, la complexité pour accéder à une valeur dans un tableau , la pousser ou la sauter est de O (1) . Tandis que la recherche linéaire dans un tableau via son index, comme on l’a vu précédemment, présente une complexité de O (n) .
De plus, comme un changement ou unshift d'une valeur en provenance ou à l'avant d'un tableau nécessite réindexation chaque élément qui le suit ( par exemple la suppression d' un élément à l' index 0 nécessite élément réétiquetage à l' index 1 comme index 0, et ainsi de suite), ils ont une complexité de O (n) . Le changement d'étiquette est effectué du début à la fin de la matrice.
Clé - objets appariés de valeur
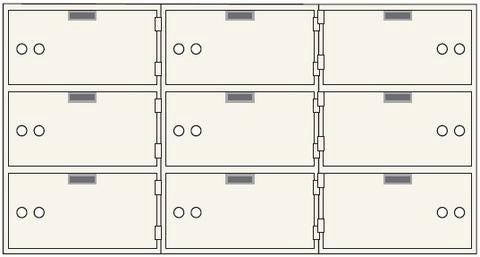
L'accès , l' insertion ou la suppression d' une valeur à l'aide d'une clé est instantanée et ont donc une complexité de O (1) . La recherche dans chaque «boîte de dépôt» d'un article spécifique en utilisant chaque clé disponible est essentiellement une recherche linéaire . Et donc, il a une complexité de O (n) .
Conclusion
La complexité est plus qu'un sujet de discussion sur les algorithmes établis et les structures de données. Utilisé judicieusement, il peut s'avérer un outil utile pour évaluer l'efficacité du travail que vous effectuez et le code que vous créez pour résoudre vos problèmes.